مقدمة: تتحدث المقالة عن احد خوارزميات تصنيف البيانات وهى خوارزمية ID3 ونستعرض فيها شرح للخوارزمية وكيفية تطبيقها والقصور فيها
تعريفها هى عبارة عن خوارزمية تستخدم لتصنيف البيانات –حيث مدخل الخوارزمية مجموعة من البيانات والناتج هو قاعدة classifier تستطيع من خلالة تصنيف بيانات جديدة لم تستخدم من قبل كنوع من التنبؤ لهذة للبيانات الجديدة – هذا الclassifier يكون على شكل شجرة tree structure لذا سميت decision tree ويمكن تحويلها الى مجموعة من القواعد rules لذا اطلق عليها ايضا اسم decision rules
استخدامه اكل ما يخص مشاكل التصنيف (من تحليل الدخل income Analysis-تصنيف امراض –تصنيف صور—)
مبدأ الخوارزمية تستخدم الخوارزمية مبدأ Divide and Conquer فكرة المبدا تقسيم المشكلة الى اجزاء ويحل كلها منها على حدة ثم يتم تجميع الحل هناك قصة فى نهاية المقالة عن المبدأ ( لا تنسون قرأتها والاستفادة منها)
كيفية استخدامها لنفترض ان لدى مجموعة من البيانات كبيرة –كمثال مصغر كما بالجدول (1)
شكل (1) Decision tree example
البيانات فى العادة تكون كبيرة لذا سوف نمثلها على هيئة جدول بة مجموعة من الامثلة instances كل مثال فى صف record و يتم تقسيمها من حيث الاعمدة columns الى:-
1) مجموعة خصائص Attributes وكل Attribute لها مجموعة من القيم Values
فمثلا Travel Cost هى خاصية Attribute وتأخذ اى من القيم الثلاثة( Cheap-Standard-Expensive )، وهكذا لباقى خصائص الجدول .
2) مجموعة الكلاسات Classes وهى ايضا خاصيةAttribute ولكنها تعتبر ناتج تصنيف مجموعة من Attributes مع بعضها وفى العادة مشاكل التصنيف تكون بها كلاس واحد لكن يمكن ان تكون اعقد وبها اكثر من كلاس.
فمثلا جدول (1) عبارة عن بيانات لتحديد وسيلة الموصلات المناسبة لكل شخص حسب خصائص Attributes معينة .
انواع الخصائص Attributes:
هناك انواع لل Attributes يتم تصنيفها من حيث القيم Values التى تأخذها فمثلا:
اذا كانت القيم لخاصية Attribute ما -يمكن التعبير عنها على صورة (0,1) True or False فتسمى Binary Attributes مثل الخاصية Gender فتأخذ قيم اما male, female
اذا كانت الخاصية تأخذ قيم يمكن التعبير عنها دون ان يوجد ترابط بين قيمها تسمى Ordinal Attribute مثل الخاصية الكلاس Transportation mode وتأخذ القيم Bus-Train-Car فلا يوجد علاقة بينهم
هناك انواع كثيرة اخرى للخصائص يمكن البحث عنها .
كيفية استخدام ال Decision Treeالجدول السابق يمكن اختصارة الى قاعدة تصنيف classifier كما بالصورة شكل (1) Decision tree example
ومن هذة القاعدة classifier يمكن ان استنتج قيم لبيانات لم نراها من قبل فنفترض ان لدينا مجموعة من الاشخاص واريد التنبؤ لهم ما هو طريقة الانتقال المناسبة لهم Transportation mode كما بالجدول (2) فلدى مجموعة بيانات جديدة لمجموعة من الاشخاص واريد ان اعطى كل منهم نوع وسيلة المواصلات الملائمة لة (هذة البيانات الجديدة نطلق عليها Test Set اى بيانات اختبارية حيث استطيع بها تحديد واختبر مدى جودة القاعدة الclassifier التى انتجتها)
جدول (2): مجموعة من البيانات الجديدة التى ليس لها كلاس واريد التنبؤ بة
لكن كيف هذة القاعدة classifier تعبر عن الجدول وكيف يمكن استخدامها فى التنبؤ بوسيلة الموصلات الملائمة اذا كانت مفقودة
لاستخدام القاعدة سوف ابدأ ب Root node فى الشكل (1) وهى Travel cost/km ثم ابدأ التفرع منها حسب قيمة كل خاصية Attribute الى ان انتهى الى Leaf node والتى تعتبر الكلاس للبيانات التى تتبعت قيمها فى القاعدة.
فمثلا لو اردت التنبؤ للشخص Alex عن طريقة المواصلات الملائمة لة سوف ابدأ ب Root node فى الشكل (1) وهى Travel cost/km ثم التفرع سوف اجد ثلاث خيارات امامى اما expensive او standardاو cheap لكن Alex من جدول (2) قيمة ال Travel cost/km لة هى stranded لذا سوف يكون تصنيف المواصلات لة هو Train
هكذا الحال عندما اريد التنبؤ لنوع المواصلات لدى بقية الاشخاص.
يمكن تحويل decision tree الى مجموعة من القواعد Rules Set باستخدام if –else فالشكل (1) يمكن كتابتة كالاتى:
طبقا لمجموعة القواعد السابقة والdecision tree فى شكل (1) فيمكن التنبؤ لبقية Test set كما بالجدول (3)
جدول(3):نتيجة تطبيق Rule Set and decision tree
كيف انشىء Decision Tree
يتم انشاء الdecision tree اعتمادا على اختيار افضل خاصية Attribute يمكن ان تقسم الTraining set بحيث يقل عمق الشجرة فى نفس الوقت الذى يتم فية تصنيف للبيانات بشكل صحيح
كيف يتم اختيار افضل Attribute للتفرع منها هذا يجعلنا نتطرق لطرق لحساب كيمة التشوية فى البيانات ويعرف على انة Entropy
اذا لدى مجموعة من البيانات فى جدول عبارة عن امثلة instanceوكل مثال لة Attributes وكلاس class فأننا نقول على جدول ما انة Pure او homogenous اذا كان كل الامثلة فى الجدول تأخذ نفس قيمة الكلاس كما بالشكل التالى
اما اذا كانت الامثلة فى الجدول تاخذ قيم مختلفة للكلاس فيعرف الجدول على انة impure or heterogeneous
هناك اكثر من طريقة لحساب impurity منها:
Entropy : ويحسب بالمعادلة الاتيه
حيث pj هو احتمالية اختيار الكلاس j
نبدأ نتعلم كيف نحسب الاحتمالية لكل كلاس اولا ثم نتعلم كيفية حساب Entropy
بداية نرجع للجدول لاجل التطبيق
لحساب احتمالية( Attribute( class والتى هى Transportation mode انظر الى الجدول واحدد عدد القيم التى تأخذها هذة الخاصية سوف نجد انها تأخذ ثلاث قيم ( car-bus-train) سوف احسب عدد حدوث كل قيمة نسبة لعدد الامثلة الكلى فى الجدول والذى هو 10 لذا فاحتمال probability لكل قيمة تكون
الان بعد معرفة كيفية حساب impurity نستطيع ان ندخل على كيفية انشاء ال decision tree فى البداية قلنا مسبقا ان مبدأ الخوارزمية هو divide and conquer لذا سوف نبدأ نتقسيم الTraining Set فى الجدول حسب كل Attribute حتى استطيع حساب افضل Attribute ابدأ بها ك Root node :
نبدأ اول خطوة فى الخوارزمية :
نبدأ نحسب لكل Attribute فى Training set قيمة ال information gain ما هذة القيمة وكيف يتم حسابها ؟هذة القيمة التى تحدد لنا افضل Attribute يمكن ان نقسم بها Training set كيف يمكن حسابها سوف نستخدم impurity measure التى تحدثنا عنها مسبقا لحسابها
لنفترض اننا بدأنا بخاصية Attributeالتى هى Travel cost فأننا سوف نأخذها على حدة مع الكلاس ونقسمها حسب كل قيمة لها فى جدول مصغر –بشكل مبسط اكثر نحن لدينا ثلاث قيم يأخذها Travel cost وهىCheap- Standard-Expensive لذا سوف يكون لدينا ثلاث جداول مصغريين كما بالشكل التالى
لكل جدول مصغر سوف نحسب impurity measure بأى طريقة منهم سواء classification error Entropy, Gini index
سوف احسب وليكن Entropy لكل جدول مصغر
1
2
3
4
5
Entropy(Cheap)=–(4/5)log(4/5)–(1/5)log(1/5)=0.722
Entropy(Expensive)=–(3/3)log(1)=0
Entropy(Travel Cost)=–(2/2)log(1)=0
شرح كل ترم وقيمتة
الان بعدما قمنا بحساب information gain لل Travel Cost Attribute نكرر حسابة لكل Attributes الاخرى نحصل على الشكل التالى
والتى تلخص قيم information gain لكل Attribute على حدة
الان نحصل على الAttribute ذات الinformation gain الاعلى وتكون هى افضل Attribute
بعدما حصلنا على افضل Attribute وهى Travel Cost نضعها هى Root Node فى الشجرة
ثم نبدأ تقسيم الجدول طبقا لها لنحصل على الاتى
نجد بعد استخدام الTravel cost لتقسيم الجدول ان هناك ثلاث تفرعات فاذا كانت القيمة Expensive لا يوجد الا كلاس واحدوهو car كذلك اذا كانت القيمة Standard فايضا لا يوجد الا كلاس واحد وهو Train اما اذا كان القيمة Cheap فلدينا اكثر من كلاس لذا سوف نبدأ نكرر مرة اخرى الخطوات السابقة .
الان نبدأ iteration جديدة ونعتبر ايضا اننا سوف نبدأ ببيانات جديدة لان الامثلة التى غطتها الrule السابقة
لل Travel cost ==expensive && Travel cost ==standard سوف تلغى من training set الان.
اذن كما بالرسمة لم يتبقى لدينا الا الجدول الاول
اذن لنبدأ ننظر فية : بداية نلغى منة Travel cost ==cheap سوف يتبقى لدينا ثلاث خصائص
Gender, car ownership, income level نكرر حساب افضل Attribute يمكن ان نقسم بها الجدول عن طريق حساب information gain لكل خاصية كما سبق
اولا :نحسب Entropy للجدول الجديد
ثانيا: نحسب الinformation gain لكل Attribute على حدة Gender,car ownership,income level
سوف نجد ان افضل information gain هى للAttribute Gender لذا سوف نقسم الجدول من خلالها لنحصل على الاتى
اذن يمكن تقسم الجدول الى تفرعيين لو Gender= male يوجد لدينا كلاس واحد حصلنا على pure Table تبقى لنا لو Gender=female سوف نتفرع مرة اخرى الى ان نصل الى pure table ايضا
ونحصل على القاعدة classifier
اخيرا Main Algorithm الذى يلخص الخطوات السابقة:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
ID3(Examples,Target_Attribute,Attributes)
Createaroot node forthe tree
Ifall examples are positive,Returnthe single-node tree Root,with label=+.
Ifall examples are negative,Returnthe single-node tree Root,with label=-.
Ifnumber of predicting attributes isempty,thenReturnthe single node tree Root,with label=most common value of the target attribute inthe examples.
Let Examples()be the subset of examples that have the value forA
IfExamples()isempty
Thenbelow thisnewbranch addaleaf node with label=most common target value inthe examples
Elsebelow thisnewbranch add the subtree ID3(Examples(),Target_Attribute,Attributes–{A})
ReturnRoot
عيوب decision tree :
رغم سهولة decision tree الا ان لها عيوب كثيرة
1.عند كثرة الامثلة والبيانات ما مدى عمق الشجرة how deep to grow the decision tree
2. لا تسطيع التعامل مع البيانات المستمرة handling continuous attributes
3. ايجاد طريقة لقياس الخاصية الانسب التى تقلل عمق الشجرة وفى نفس الوقت تصنف للبيانات بشكل جيد ليس خاطىء choosing an appropriate attribute selection measure
4. لا تستطيع التعامل اذا هناك قيم لخصائص مفقودة فى اى مثال handling training data with missing attributes
5. لا يمكن التنبؤ اذا لدى اكثر من كلاس handling attributes with different costs
قصة مبدأ Divide and conquer
وفكرة المبدا تقسيم المشكلة الى اجزاء ويحل كلها منها على حدة ثم يتم تجميع الحل حقيقة مبدا جميل لحل المشاكل وهكذا يفعلون الاعداء معنا للاسف علشان نوضح المبدا راح احكى لكم قصة صغيرة وهى قصة الثور الابيض وثلاث من اخواتة ولكن باللون الاسود وهم كانوا صحبة لا يتفرقون ابدا ونتيجة لتجمعهم لم يستطع ابدا اى عدو اسد او ذئاب ان يقتربوا منهم للاسف فى يوم من الايام اجتمع الاخوة ” الثور” الذين باللون الاسود وقالوا ان الثور الذى باللون الابيض يظهر فى الظلام وبذلك فهو يعرضنا للخطر بالليل ونحن لوننا اسود فلا نظهر لذلك نفترق عنة حتى لا نتعرض للخطر وفعلا اجمعوا على ان يتركوة لوحدة وفى يوم من الايام وجد الذئاب الثور الابيض لوحدة فلم يخافوة وبدؤا بالهجوم علية وياكلون لحمة والاخوة الذين باللون الاسود يشاهدون ويراقبون ولا يدافعون عن اخوهم وفى اليوم الذى يلية هجم الذئاب على الثلاث باللون الاسود لان عددهم قل وكانت النتيجة ان احدهم مات وفى اليوم الذى يلية اصبح اسهل لان العدد اصبح اثنين وهكذا حتى اخر واحد وكانت المقوله الشهيرة لاخر واحد فيهم عندما هاجمه الذئاب لقد اوكلت عندما اوكل الثور الابيض—- والتى تعنى لقد مت ليس الان ولكن عندما كنت اراقب اخى يموت امام عيينى واشاهدة ولم افعل شيئا“
المراجع:
المرجع الاول هو اساس كتابة هذة المقالة مقتبس منة معظم الشرح -في نهايتة اكواد ومراجع بأسماء الكتب مرجو للمهتميين زيارتة للتعلم منة











 شكل (1) Decision tree example
شكل (1) Decision tree example






















 شكل (1) Decision tree example
شكل (1) Decision tree example






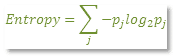























اترك تعليقك